
Funding Opportunities
Region 1 supports a wide variety of activities by supporting local Sectional activities. Sections should look here to obtain regional support!
Region 1 Student Branch Funding

Get the IEEE app today!
Make IEEE Your Professional Home!
Announcements
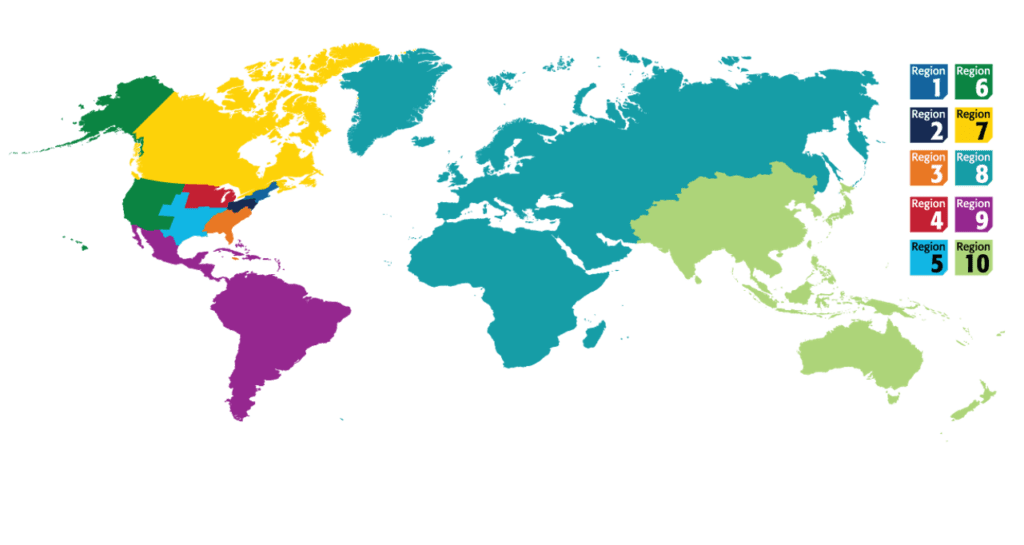
IEEE Region 1 and Region 2 will be merging into one region!
IEEE Region 1 is the home to the IEEE organizational units in the north-eastern part of the USA and is comprised of 22 Sections including: Binghamton, Berkshire, Boston, Buffalo, Connecticut, Green Mountain, Ithaca, Long Island, Maine, Mid-Hudson, Mohawk Valley, New Hampshire, New Jersey Coast, New York, North Jersey, Princeton/Central Jersey, Providence, Rochester, Schenectady, Springfield, Syracuse, and Worcester County.
IEEE Region 2 is composed of four geographical Areas in …

2024 IEEE World Forum on Public Safety Technology (WF-PST)
Join us for the inaugural 2024 IEEE World Forum on Public Safety Technology (WF-PST), a ground-breaking event dedicated to addressing current and future needs in public safety technology. Explore advancements in existing and emerging technologies, discover new research, and gain insights into breakthroughs shaping the …

IEEE Rising Stars 2024 – Fireside Chat with Dr. Vint Cerf
IEEE Rising Stars 2024 – Fireside Chat with Dr. Vint Cerf, Chief Evangelist at Google
Topic: Interplanetary Internet Interviewer: Ramesh Nair – Intel Corp.
Leadership








